




Recap
In my previous post, I wrote about using GitHub Actions in conjunction with your data setup, specifically with your CI workflows. GitHub Actions can be helpful for teams looking to lessen their dependency on dbt Cloud (and to save money). Although there is a little bit of setup, the only prerequisites are knowing your way around a YAML file and having a basic knowledge of Python.
Today, I’m going to follow up from that post and talk about enhancing the previous setup with 1) some refactoring of the previous CI workflow and 2) starting a workflow that gets triggered after a pull request is merged.
Refactoring our CI workflow
The key changes I made to the previous code include:
- Installed the package
actthrough the Codespacesdevcontainer.jsonconfiguration file. This allowed me to run and test my GitHub Actions file locally without having to push a bunch of commits to my repo. - Installed
venvand added arequirements.txtfile. Previously, I had a step to just install dbt. I opted to install dbt along with other packages usingrequirements.txtsince this is a common practice in engineering organizations. - Removed the
profiles.ymlfrom the repo and configured the CI dbt profile directly within the GitHub action workflow file. In the previous iteration of this, we checked in theprofiles.ymlfile to the repository, but your organization may prefer not to do that. Also, this method allowed me to customize the name of the schema (aka “dataset” in BigQuery), which I describe in more detail next. - Named the BigQuery schema/dataset using a prefix and the pull request number. You’ll notice this line in the dbt profile configuration:
PR_SCHEMA="${{ env.SCHEMA_PREFIX }}_${{ github.event.number }}". In this case, I’m using the prefixdbt_oriana_ga_prbefore each PR number. You may want to use a prefix likedbt_<your name/username>_<your project name>_pr. When GitHub Actions kicks off this workflow, it’ll append the number associated with the pull request to the schema prefix. This is helpful in differentiating multiple pull requests in the same codebase!

Here is the newly updated dbt-ci.yml file. To use this, you’ll also have to add a requirements.txt file and create a new GitHub secret containing your BigQuery project ID. To see everything that’s changed, here is the pull request.
name: Run dbt test suite on PRs
on:
pull_request:
types:
- opened
- reopened
- synchronize
- ready_for_review
push:
branches:
- '!main'
jobs:
build:
runs-on: ubuntu-latest
env:
DBT_PROFILES_DIR: ./coffee_shop # Specify the location of the profiles.yml file
DBT_PROJECT_DIR: ./coffee_shop # Specify the location of the project directory
SCHEMA_PREFIX: dbt_oriana_ga_pr # Specify the prefix for the PR schema
PROJECT_ID: ${{ secrets.BIGQUERY_PROJECT_ID }} # Update with the name of the secret containing the project ID
SERVICE_ACCOUNT_KEY: ${{ secrets.BIGQUERY_SERVICE_ACCOUNT_KEY }} # Update with the name of the secret containing the service account key
steps:
- name: Checkout PR code
uses: actions/checkout@v4
with:
ref: ${{ github.event.pull_request.head.sha }} # Checkout the specific commit of the pull request
- name: Create GCP keyfile JSON
run: | # Creates the keyfile and moves it to the profiles directory
echo "$SERVICE_ACCOUNT_KEY" > gcp-credentials.json
mv gcp-credentials.json $DBT_PROFILES_DIR
- name: Set up Python
uses: actions/setup-python@v2
with:
python-version: 3.11 # Choose the Python version you need
- name: Install requirements
run: |
pip install -r requirements.txt
- name: Configure dbt Profile
run: |
PR_SCHEMA="${{ env.SCHEMA_PREFIX }}_${{ github.event.number }}"
echo "
coffee_shop:
target: ci
outputs:
ci:
type: bigquery
method: service-account
keyfile: $DBT_PROFILES_DIR/gcp-credentials.json
project: $PROJECT_ID
dataset: $PR_SCHEMA
threads: 4
timeout_seconds: 300
" > $DBT_PROFILES_DIR/profiles.yml
- name: Run dbt build
run: |
dbt build --profiles-dir "$DBT_PROFILES_DIR" --target ci --project-dir "$DBT_PROJECT_DIR"
Code language: PHP (php)Adding a new workflow when merging PRs
When a pull request is merged, you’ll probably want to trigger a set of actions, including:
- running your new changes in production
- updating your dbt docs (which you can host on GitHub Pages!)
- cleaning up your PR schemas
You can see the dbt-merge.yml file in the repo here. Below is the workflow in full.
name: Run production models, update dbt docs, and clean up CI schemas when a PR is merged
on:
pull_request:
types:
- closed
push:
branches:
- main
env:
DBT_PROFILES_DIR: ./coffee_shop # Specify the location of the profiles.yml file
DBT_PROJECT_DIR: ./coffee_shop # Specify the location of the project directory
SCHEMA_PREFIX: dbt_oriana_ga_pr # Specify the prefix for the PR schema
PROJECT_ID: ${{ secrets.BIGQUERY_PROJECT_ID }} # Update with the name of the secret containing the project ID
SERVICE_ACCOUNT_KEY: ${{ secrets.BIGQUERY_SERVICE_ACCOUNT_KEY }} # Update with the name of the secret containing the service account key
jobs:
run-production-models:
if: github.event.pull_request.merged == true
runs-on: ubuntu-latest
steps:
- name: Checkout PR code
uses: actions/checkout@v4
with:
ref: ${{ github.event.pull_request.head.sha }} # Checkout the specific commit of the pull request
- name: Create GCP keyfile JSON
run: |
echo "$SERVICE_ACCOUNT_KEY" > gcp-credentials.json
mv gcp-credentials.json $DBT_PROFILES_DIR
- name: Set up Python
uses: actions/setup-python@v2
with:
python-version: 3.11 # Choose the Python version you need
- name: Install requirements
run: |
pip install -r requirements.txt
- name: Configure dbt Profile
run: |
echo "
coffee_shop:
target: prod
outputs:
prod:
type: bigquery
method: service-account
keyfile: $DBT_PROFILES_DIR/gcp-credentials.json
project: $PROJECT_ID
dataset: dbt_oriana_ga_prod
threads: 4
timeout_seconds: 300
" > $DBT_PROFILES_DIR/profiles.yml
- name: Run dbt
run: |
dbt build --profiles-dir "$DBT_PROFILES_DIR" --target prod --project-dir "$DBT_PROJECT_DIR"
- name: Generate dbt docs
run: dbt docs generate
- name: Deploy dbt docs to GitHub Pages
uses: peaceiris/actions-gh-pages@v3
with:
github_token: ${{ secrets.GITHUB_TOKEN }}
publish_dir: ${{ env.DBT_PROJECT_DIR }}/target
- name: Install Google Cloud SDK
run: |
echo "deb [signed-by=/usr/share/keyrings/cloud.google.gpg] <https://packages.cloud.google.com/apt> cloud-sdk main" | sudo tee -a /etc/apt/sources.list.d/google-cloud-sdk.list && curl <https://packages.cloud.google.com/apt/doc/apt-key.gpg> | sudo gpg --dearmor -o /usr/share/keyrings/cloud.google.gpg && sudo apt-get update -y && sudo apt-get install google-cloud-sdk -y
- name: Authenticate to GCP
uses: google-github-actions/auth@v0.4.0
with:
credentials_json: '${{ secrets.BIGQUERY_SERVICE_ACCOUNT_KEY }}'
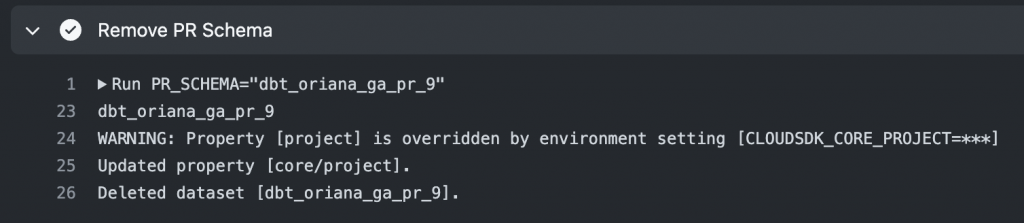
- name: Remove PR Schema
run: |
PR_SCHEMA="${{ env.SCHEMA_PREFIX }}_${{ github.event.number }}"
echo $PR_SCHEMA
gcloud config set project $PROJECT_ID
gcloud alpha bq datasets delete $PR_SCHEMA --quiet --remove-tables
Code language: PHP (php)To run new changes and/or any models in production, most of the code is pretty similar to the dbt-ci.yml workflow. The only thing that changes is the dataset field in the “Configure dbt Profile” step, which you can update to the name of your production dataset. In my case, I’m using dbt_oriana_ga_prod. Depending on the set up of your staging and production models, you may also need to configure a different BigQuery project (or $PROJECT_ID) for this workflow.
Publishing dbt docs
GitHub Pages offers a free way of hosting static pages, which we can use to host our dbt documentation. Additionally, you can set up a GitHub Action to automatically push new documentation when you merge your code. We do this with the steps “Generate dbt docs” and “Deploy dbt docs go GitHub Pages.”
After this code is merged, there is an additional step to actually publish the dbt documentation. Navigate to Settings > Pages for your repository. Under the section “Build and deployment”, select “Deploy from a branch” for “Source”. Under “Branch,” look for a branch called “gh-pages”.

The URL of this will look something like https://<username or GitHub organization>.github.io/<repo name>. In my case, it’s https://oreoana.github.io/aec-github-actions/.
Note: Private GitHub Pages are currently only available for Enterprise GitHub accounts.
Tidying up your data warehouse
As you can imagine, if your team is creating pull requests on a regular basis and you’ve implemented a similar CI workflow, your data warehouse might start to feel a little cluttered with all these PR schemas. The last three steps in the dbt-merge.yml workflow allow us to install the Google Cloud SDK, authenticate using your service account key, and delete the schema associated with your pull request. Since we put in place a naming convention for our PR schemas, we are able to identify the correct schemas to remove!
Note: In the command to delete BigQuery datasets gcloud alpha bq datasets delete $PR_SCHEMA --quiet --remove-tables, we use the quiet flag to skip the confirmation prompt and the remove-tables flag to also remove the underlying tables in the dataset. Additionally, at this point of writing this post, this command is in alpha mode and may be subject to change without notice.
Conclusion
Some of our readers have expressed interest in seeing how we could expand the GitHub Actions workflow to use the manifest.json file to be able to keep track of state and run only modified models. We hope to write about this soon!
Let us know if you and your team start to implement GitHub Actions into your development workflows. As always, we love to hear from you, so drop us a line!

