




This content is an excerpt from one of our lectures in our Analytics Engineering Course. Applications are now open for our Feb — April cohort.
If you’re working with dbt, Airflow, or Dagster, it won’t take you long to come across the concept of DAGs — directed acyclic graphs. But what exactly is a DAG? And why are they such an important concept in data engineering?
Let’s start with the graph part — we’re not talking about a chart here! Instead, this is a “graph theory” kind of graph, which is a way of representing objects and the relationships between them. In data engineering, the objects (or “nodes”) represented in the graph are usually a task that a computer needs to execute (“build this table”, “extract this data”). The relationships between the objects are the dependencies between them (“this needs to happen before that”) – as such, the relationships are directed. Finally, you can’t have any cycles in a DAG — that’s the acyclic part of it.
DAGs are often visualized as as flow-chart-like diagrams, with the tasks shown as boxes on the diagram, and the dependencies shows as arrows.
If none of that made sense, that’s totally fine! Let’s jump into a real-life example to learn some more principles, and it might click. We’ll look at an activity I do multiple times a day, making coffee, represented as a DAG:
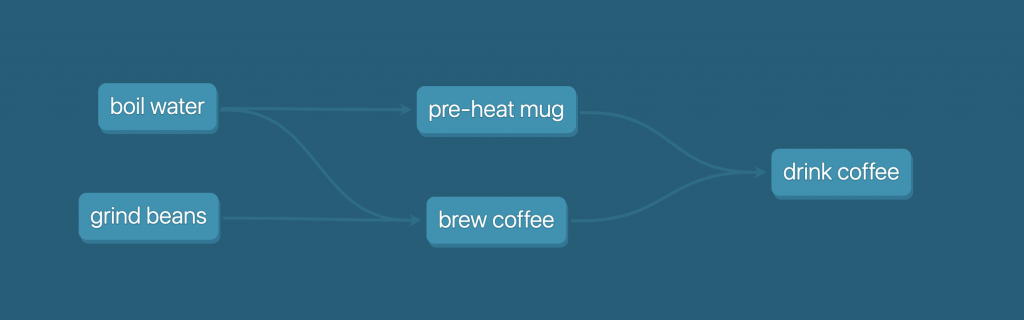
Here, my nodes are tasks like “boil water”, and the arrows show the dependencies. From this visual representation, we can see that I need to boil water before I can pre-heat my mug, or brew my coffee. But to brew my coffee, I also need to grind my beans. Then, once I’ve preheated my mug and brewed my coffee, I can move onto drinking it. This is actually easier to show visually than to explain in words!
Some programs may get you to draw arrows to connect tasks in a DAG. However, in data engineering programs, it’s more likely you’ll declare these relationships in code. In dbt in particular, the dependencies between tasks are inferred via the ref function. In Airflow, you declare the dependencies explicitly, like so (there’s many ways to achieve this in Airflow!)
boil_water >> pre_heat_mug boil_water >> brew_coffee grind_beans >> brew_coffee pre_heat_mug >> drink_coffee brew_coffee >> drink_coffee
You should be able to answer each of these questions by now:
- What does DAG stand for, and what does each word mean?
- What is a node in a DAG?
- What do the arrows between nodes represent?
- What are some ways that DAGs are defined?
Now that we have the basics under control, let’s run through some thought experiments so we can understand the real value of DAGs!
- What happens if I’m making coffee on my own (one “worker”) and can’t multitask? What order should I do tasks in?
I can choose whether I boil water, or grind the beans first. Both have to be done before I can move onto the next task(s), but it doesn’t matter in which order. Then, I can choose whether I pre-heat the mug, or brew the coffee next. Drinking the coffee always comes last. - What happens if my housemate helps out (two workers)? How can we efficiently allocate tasks?
If I have two workers, one of us can boil water while the other grinds beans. Then, one can pre-heat the mug, while the other brews the coffee. In general, we can make the coffee more quickly by parallelizing some tasks (i.e. performing tasks in parallel) - What happens if I have two housemates help out (three workers)?
We have more workers than we have concurrent tasks, so at any time there will be one person not doing anything (hopefully me!).
We just learned some really important concepts:
- Workers: the number of tasks we can process at once. Also referred to as “threads” available
- Parallelize: working on multiple tasks at once
As human beings, we can answer the above questions pretty easily for this DAG — it feels relatively intuitive. We could even write out the order tasks given the number of workers available. But what happens if our DAG is hundreds, or thousands of tasks (and many data engineering DAGs are!), and we have a dozen workers?
Fortunately, computers have our back: by understanding the dependencies between tasks, and the number of workers available (sometimes referred to as the “threads” available, or maximum concurrency), computers can figure out the most efficient ordering of tasks, and how to perform tasks in parallel to get things done more quickly.
Want to go even deeper? As a next step, check out this great article on efficient DAG algorithms from the dbt team. Or, consider joining us for our next Analytics Engineers Club cohort!